When "Private" Isn't Private: The Hidden Bugs Inside Differential Privacy Deployments
We audited 11 widely-used differential privacy libraries and found 13 bugs. Here's what broke, why existing tools miss it, and how to fix it.
6 minutes
Differential privacy has a compelling promise: deploy it correctly and you can give your users a mathematically provable guarantee that their data is protected. Regulators are paying attention. Enterprises are investing. The field is genuinely maturing.
But there's a gap that the industry has been slow to confront. The mathematics of differential privacy is sound. The implementations, increasingly, are not.
We know this because we went looking. In a new paper recently accepted to PETS 2026, we audited 11 of the most widely used open-source differential privacy libraries in the world. We found 13 previously unknown privacy violations across libraries maintained by organisations including Microsoft, IBM, and Meta. These are not obscure theoretical corner cases. They are implementation flaws in production libraries that practitioners rely on when they want to build something private.
The teams behind these libraries are extremely talented. Many are the authors of the foundational research on which the field is built. That's precisely the point. These bugs are not the result of carelessness. They reflect a category of error that even experts miss—and that the ecosystem has had no systematic way to catch. Until now.
A Quick Primer On Differential Privacy
Differential privacy is a mathematical framework that ensures the outcome of an analysis does not meaningfully change whether any single individual's data is included or not. In practical terms, this is what allows organisations to analyse sensitive datasets, such as health records, transaction histories, or usage logs, without exposing information about any specific person.
That guarantee holds only when the implementation is correct. And as we'll show, correctness in practice is much harder than it sounds.
The Math Is Fine. The Plumbing Leaks.
Privacy violations in differential privacy deployments rarely come from the noise-generating mechanisms themselves. The Laplace mechanism, the Gaussian mechanism, the exponential mechanism—these are mathematically well-understood and generally well-implemented in core frameworks like OpenDP.
The problem is in what surrounds them.
A real-world DP pipeline is mostly unglamorous: preprocessing steps that clip data, calculate sensitivities, configure batch sizes, pass parameters around, and post-process outputs. Because this isn't the mathematically interesting part, it receives less scrutiny. That's where things go wrong.

What We Found
The bugs we uncovered were not conceptual misunderstandings of differential privacy. They were engineering mistakes—subtle, easy to miss, and consequential.
In SmartNoise Synth, developed at Microsoft, the covariance estimator declares a sensitivity based on sanitised data, but computes the actual output on the original, uncensored values. A single variable name—data used where newdata should have been—means the declared sensitivity can be orders of magnitude smaller than the true one. The math is fine. The plumbing leaks.
In Diffprivlib, IBM's differential privacy library, a copy-paste error in the linear regression implementation means the lower bound of a data range is used twice, where the upper bound should appear in one of those places. It's the kind of mistake a careful human reviewer would probably miss on ten passes through the code.
In Opacus, Meta's framework for differentially private deep learning, the expected batch size is derived from the length of the dataset—a quantity that's private under the add-or-remove model Opacus itself assumes. This was flagged on GitHub over two years ago and remains unpatched.
In Synthcity, a synthetic data library from the van der Schaar Lab at Cambridge, the output of an exponential mechanism is used to index into a private, un-noised list, and the result controls a branch in the code. The execution path itself reveals what should have been private.
The lesson isn't that these libraries are bad. It's that even mature, well-reviewed codebases contain this class of bug and that the field has had no systematic way to catch it.
Why Existing Approaches Don’t Catch This
Developers currently have limited ways to verify the correctness of differential privacy implementation.
Formal verification can mathematically prove that code satisfies differential privacy, but it requires rewriting systems in specialised languages that most production teams working in Python will never adopt.
Statistical auditing treats a DP pipeline as a black box and tries to detect leakage empirically—but as pipelines become multi-stage and high-dimensional, this becomes computationally intractable and often only signals that "something is leaking somewhere," without telling you where. Manual review can't keep pace with the complexity of modern data pipelines.
This creates a growing gap between the privacy organisations believe they are providing and the privacy their systems actually deliver. That gap is rarely visible to non-experts, which makes it especially dangerous in regulated or high-trust environments.
It is what motivated the development of a tool that can detect mistakes early, consistently, and at negligible computational cost.
A Different Kind of Audit
Our tool, Re:cord-play (released as an open-source Python package, dp-recorder), takes a different approach to pressure test the plumbing. It works on real Python code, integrates with standard testing tools like pytest and CI pipelines, and pinpoints bugs at the exact mechanism call where they occur—not just "something is wrong somewhere."
The core insight is structural. A well-formed DP pipeline has a recognisable shape: preprocessing, mechanism, postprocessing, repeat. The mechanisms—the Laplace, Gaussian, and exponential—are the mathematically verified parts. What you need to test is whether the surrounding code uses them correctly when the underlying data changes.
Re:cord-play checks this through a record-and-replay technique. Run the pipeline once on a dataset and record what each DP mechanism outputs. Freeze those outputs. Run the pipeline again on a neighbouring dataset—one that differs by a single individual. If anything in the control flow, parameter logic, or downstream behaviour diverges between the two runs, that divergence can only come from one place: data-dependent behaviour that should not exist.
In other words, the tool asks a straightforward question: does the system behave differently when one person's data changes? If the answer is yes, privacy has already failed.
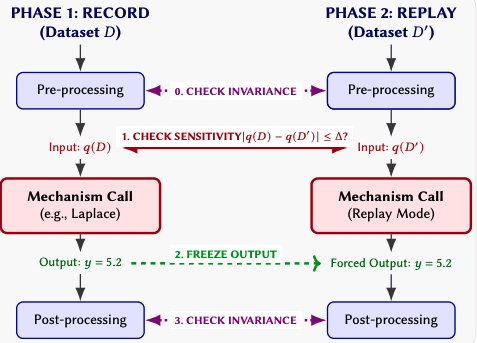
Because randomness is frozen, violations are deterministic and reproducible. The framework identifies exactly where in the code the problem lives. Each of the 12 audits in our paper targeted a library we had no insider knowledge of and took only a few days. Auditing our own code took hours. That's the kind of leverage a mature engineering practice needs.
Why We Open-Sourced It
We've published dp-recorder as a free, open-source Python package. That's a deliberate choice, and it reflects something we care about: the health of the ecosystem matters, not just our own implementations.
If DP is going to be the backbone of privacy-preserving AI, and it increasingly will be, then the whole stack needs to be trustworthy, not just the top of it. Several of the libraries we audited have already agreed to integrate these checks into their continuous integration pipelines. Every future code change will be automatically screened for the class of bugs we found. That matters more than the bug count itself.
We notified all affected maintainers privately and provided suggested fixes before publishing. The purpose of this work is not to point fingers, but to illuminate how easy it is to break differential privacy even inside mature, well-reviewed libraries—and to give the ecosystem a practical way to prevent it.
What This Means for Organisations Deploying DP
The PETs industry is at an important inflexion point. Differential privacy has crossed from academic curiosity to genuine production deployment. Regulators are beginning to reference specific technical standards. The ICO's anonymisation guidance, NIST's epsilon registry, and the EU AI Act's treatment of privacy-preserving techniques all point toward a world where formal privacy guarantees will be expected, not optional.
That's the right direction. But maturity brings responsibility. As DP moves from research into infrastructure, the question of implementation quality becomes as important as the choice of mechanism. A mathematical proof of privacy at the algorithm level is not a guarantee of privacy in the system.
The lesson here isn't that differential privacy doesn't work. It works. The lesson is that the gap between "correct in theory" and "correct in practice" is real, consequential, and closeable—but only with the right tools and the right level of rigour applied to the implementation layer, not just the mathematics.
The organisations that understand this distinction are the ones building something that will actually hold up.
If you are building, deploying, or relying on differential privacy, the takeaway is clear. The privacy guarantees you think you have may not be the guarantees you actually have. The system may look sealed. That doesn't mean it isn't leaking.

Where We Go From Here
dp-recorder is available now as an open-source Python package. Our hope is that it becomes a new standard for the ecosystem: a practical, reliable way to test DP implementations, prevent regressions, and reinforce trust in privacy-preserving systems.
The paper was accepted to PETS 2026. The tool is available today. If you maintain a DP library or build on one, we'd encourage you to try it.
At Oblivious, our focus is on making privacy guarantees hold in the systems people actually use. If you'd like our team to audit your differential privacy libraries, assess production implementations, or discuss how practical privacy testing fits into your development workflow, we'd welcome the conversation.
data privacy
differential privacy